11-01-2024 14:00:28
La colonne vertĂ©brale digitale est le système nerveux de l'entreprise. C'est physique ! Un ensemble de cĂ¢bles et de machines qui relient tous les pans de l'organisation Ă tous les autres pans de l'organisation et aux acteurs de l'Ă©cosystème de l'organisation. C'est un système de tuyauterie capable d'acheminer des messages d'un point Ă l'autre.
En d'autres termes, il s'agit d'avoir des voies de communication entre la comptabilitĂ©, les ventes, le marketing, … mais Ă©galement avec les clients, les fournisseurs, les distributeurs, les autoritĂ©s, …
Sans colonne vertébrale digitale il n'est point de transformation digitale !
Rappel
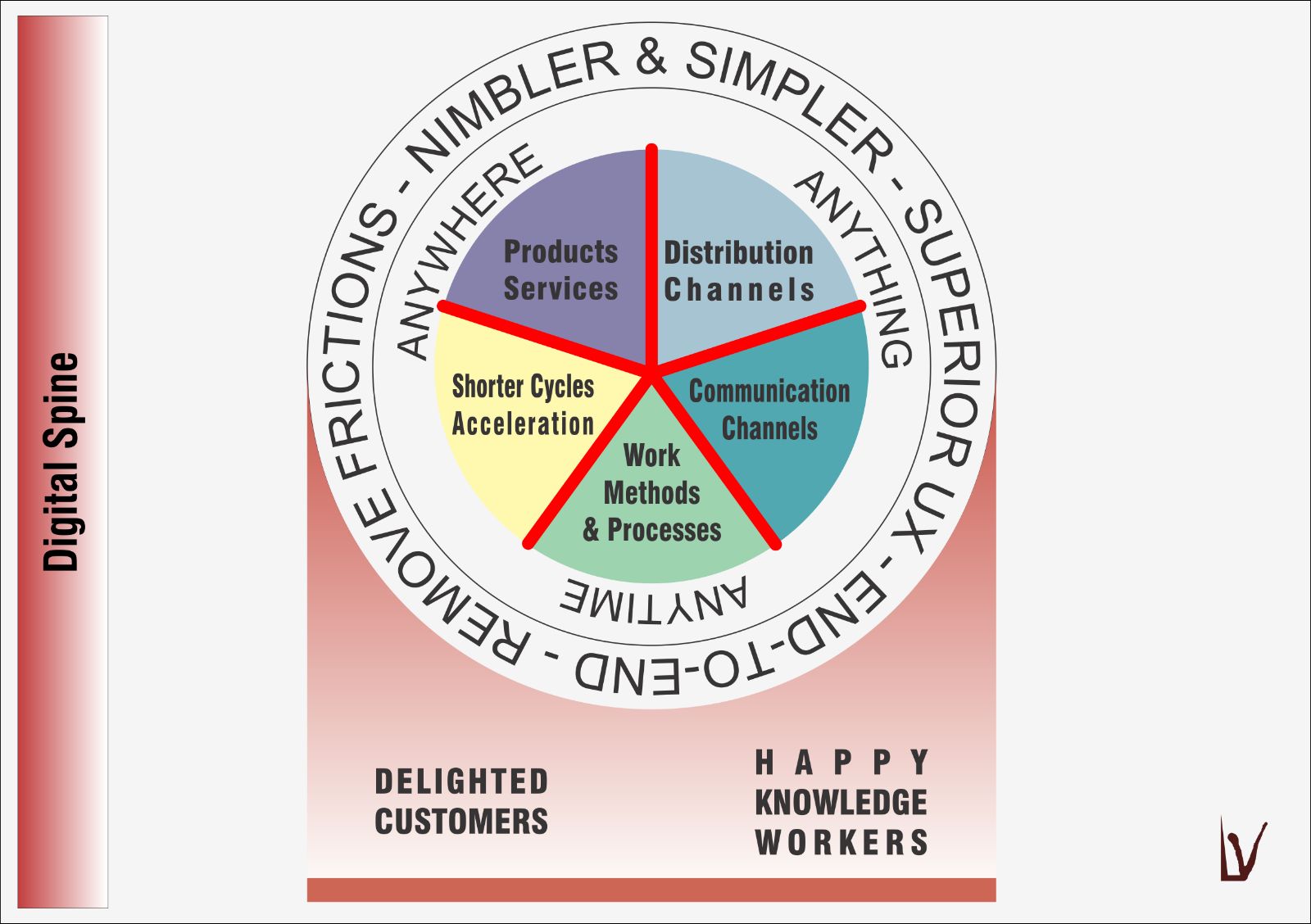
2 contraintes, 2 objectifs, 5 piliers, 1 système nerveux
Pour rappel, 2 contraintes[1] , fortes agissent sur l'entreprise :
- L'Ă©limination des frictions (tendance Ă la simplification, Ă la flexibilitĂ©, Ă l'adaptabilitĂ©, …)
- Le AAA (Anything — Anywhere — Anytime) : pouvoir tout faire, n'importe oĂ¹, n'importe quand
Pour pouvoir rencontrer et s'adapter Ă ces contraintes, on positionne 2 objectifs majeurs :
- Une orientation client véritable et sincère qui dépasse les discours convenus
- Une force de travail engagĂ©e parce qu'heureuse qui peut exercer et dĂ©velopper son expertise, qui bĂ©nĂ©ficie d'autonomie et qui puisse donner du sens Ă son travail (MAP — Mastery, Autonomy, Purpose).
Les zones de contact (lĂ oĂ¹ le combat va s'engager) sont dĂ©nommĂ©es les piliers qui sont au nombre de 5 :
- Les produits et services
- Les canaux de distribution
- Les canaux de communication
- Les mĂ©thodes de travail, l'organisation interne, les processus, …
- L'accélération des cycles
La colonne vertĂ©brale est cette Ă©toile qui apparaĂ®t et qui relie les organes internes de l'entreprise ainsi qu'elle la connecte Ă son monde extĂ©rieur selon les 5 zones de contact prĂ©sentĂ©es ci-dessus. C'est un système nerveux, parcouru d'impulsions. Que vous voyiez cette colonne vertĂ©brale digitale comme un ESB ― Enterprise Service Bus n'est qu'une forme de matĂ©rialisation.
L'Ă©pine dorsale
Pour que le digital puisse se développer il est INDISPENSABLE de disposer d'un système nerveux digital dont l'objectif est (1) de relier les organes entre eux – entendez départements – mais aussi (2) de connecter l'organisation aux autres organismes qui composent le système dont elle fait partie, le monde donc dans une économie globalisée.


C'est au travers de ce système nerveux digital qu'ont lieu les Ă©changes digitaux. L'organisation continue Ă entretenir d'autres types d'Ă©changes, physiques ceux-lĂ , mais le processus de digitalisation et de dĂ©matĂ©rialisation exerce une pression pour migrer les Ă©changes de la sphère physique Ă la sphère digitale au fur et Ă mesure de son propre dĂ©veloppement. Il s'agit d'Ă©changes bidirectionnels, entrants et sortants, qu'il est facile de se reprĂ©senter au travers de l'exemple d'une imprimerie digitale : le client peut envoyer ses documents Ă imprimer au travers d'une connexion Ă©lectronique et recevoir toutes informations utiles qui concernent sa requĂªte, la progression de son traitement, et sa livraison; l'impression papier restant, elle, physique bien entendu.
On est donc bien en présence d'un système nerveux qui relie l'ensemble des départements (les organes) de l'organisation mais également l'organisation à ses acteurs extérieurs (l'organisation est un des organismes d'un système plus large).
Un système d'impulsions
Par le système nerveux digital transitent 3 formes d'impulsions : exécutoires, sensitives (ou sensorielles), ministérielles.
Les impulsions exĂ©cutoires sont des requĂªtes d'exĂ©cution. Les sensitives (ou sensorielles) sont des impulsions de statut (senseurs). Les impulsions ministĂ©rielles, quant Ă elles, sont des requĂªtes de service qui peuvent s'apparenter Ă des impulsions exĂ©cutoires mais qui nĂ©anmoins s'en distinguent et on verra ici plus bas en quoi.
Nature d'une impulsion
L'impulsion qui parcourt le système nerveux digital a une forme. C'est un message ! Ce message est une forme de contenu disposĂ© dans une enveloppe. L'enveloppe elle-mĂªme comporte des mĂ©tadonnĂ©es concernant le contenu qu'elle contient : type de message (email par exemple), origine (dĂ©partement marketing par exemple), destination (dĂ©partement vente, par exemple), poids et/ou dimension (200 kbytes, par exemple), type de contenu (texte, image, vidĂ©o, …), urgence (prioritaire ou non, …), version, etc.
L'enveloppe est toujours la mĂªme (mĂªme structure);
le contenu, lui, varie. Le transport des impulsions
par le système nerveux ne verifie pas le contenu (sauf cas de routage
intelligent basé sur le contenu); seule l'enveloppe est examinée,
du moins dans la grande majoritĂ© des cas. Il en dĂ©coule qu'on cherche Ă
standardiser le couple enveloppe + contenu (on doit pouvoir
clairement distinguer ce qui, dans l'impulsion, appartient Ă l'enveloppe et
ce qui appartient au contenu, régulièrement appelé payload). Il
n'est pas rare d'adjoindre un troisième membre : cargo, une
sorte de cargaison passthrough.
Système réflexif
Le système nerveux digital met en place son propre monitoring et … sa propre comptabilitĂ© analytique [2] . Par monitoring, il faut entendre sa capacitĂ© Ă se rendre compte de son propre Ă©tat. Par comptabilitĂ© analytique, il faut entendre une capacitĂ© comptable gĂ©nĂ©rale capable d'attribuer son coĂ»t d'utilisation : qui a envoyĂ© quoi Ă qui, comment, en consommant quelles ressources … Cette capacitĂ© purement comptable et statistique est indispensable pour dimensionner correctement le système, pour le faire Ă©voluer avant rupture de capacitĂ©, pour, le cas Ă©chĂ©ant, refacturer en interne (ou en externe d'ailleurs) les services qu'il procure, voire mĂªme fournir une certaine gratuitĂ© des services sous des seuils convenus ou par gestion d'exceptions (accords entre parties, dĂ©finitifs ou temporaires, selon des plages de temps discutĂ©es).
Plus loin, on parlera encore de la notion de capteur.
Catalogue d'impulsions
Le système nerveux digital possède un catalogue d'impulsions possibles qui sert de cartographie générale de cette moelle épinière d'organisation.
Il est intéressant de s'en remettre à la définition que fournissent Google, Microsoft, Yahoo et Yandex de ce qu'est un catalogue pour arriver à concevoir son catalogue d'impulsions : https://schema.org/DataCatalog. On complétera cette description utilement en scrutant ce qu'en dit Wikidata (https://m.wikidata.org/wiki/Q2352616).
L'architecte informatique se régalera également de son expérience à consommer les services offerts par les plus grands fournisseurs de services généraux que sont Amazon, Google, et Microsoft, un formidable réservoir d'apprentissage pratique [3] .
On notera cette expression de la maturitĂ© digitale qui consiste Ă juger du dĂ©veloppement du système nerveux par la quantitĂ© et la variĂ©tĂ© des impulsions ― ou messages, rappelons-le ― qu'il supporte. C'est une mesure juste et objective.
Cependant, cette mesure doit s'accompagner d'une rĂ©flexion intense sur la complexitĂ© du système. Il s'agit moins ici de la nature de ce qui est compliquĂ© que de la nature de ce qui est variĂ© et qui forme de multiples combinaisons, imbrications et relations (voir Ă ce titre l'Ă©tymologie du mot «complexe» — qui embrasse des Ă©lĂ©ments divers et entremĂªlĂ©s). La complexitĂ© croissante d'un système est une mesure de sa sophistication mais Ă©galement de son entropie (2ème principe de la thermodynamique).
Pour que le système nerveux digital reste flexible et adaptatif il doit faire l'objet d'une attention particulière et il ne peut Ăªtre immunisĂ© face Ă son propre refactoring. Sans ce refactoring le système se sclĂ©rose. L'imbrication intime d'impulsions (une impulsion qui a besoin d'une autre impulsion, un service utilisant un autre service) est un risque important de sclĂ©rose [4] . C'est la raison essentielle et primordiale de la promotion du principe de dĂ©couplage qu'il n'est pourtant pas possible d'appliquer dans tous les cas (principe d'autonomie ou d'indĂ©pendance : un (micro-)service doit rester complètement indĂ©pendant)
Quand on parle de catalogue d'impulsions ou de services il est indispensable de le faire dans son aspect dynamique. Un catalogue vit. Il se consulte. On y fait des recherches. Il permet l'Ă©change. On y rend possible des simulations et essais. Il possède sa propre documentation (par exemple sa manière d'y souscrire, ses conditions d'utilisation, …) et celle de toutes les impulsions (paramètres d'utilisation, mais aussi coĂ»t si applicable parmi bien d'autres choses). Ceux qui se sont dĂ©jĂ servis de la console Amazon, ou Google, ou Microsoft, ou Deezer, ou Spotify, … ont une idĂ©e assez pragmatique de ce qui est dĂ©crit ici.
Cycle de vie des impulsions
Par l'intégration de ce qui est appelé le système réflexif, et singulièrement son principe de comptabilité analytique (ce que j'appelle le principe du caissier), on détectera objectivement les impulsions utilisées et les impulsions qui ne le sont pas, plus ou peu. Les systèmes ayant une tendance naturelle à se complexifier (voir ci-dessus) il en découle une forme d'inflation économique : le système devient économiquement lourd ! Cette forme d'inflation est naturelle. Il est inutile de vouloir y échapper. Vous ne pourrez pas y échapper.
Dans les faits, on note une tendance spontanĂ©e Ă la multiplication des impulsions diffĂ©rentes, un emphysème qu'il faut garder sous contrĂ´le. Sans cette maĂ®trise du système nerveux digital il s'Ă©croule tĂ´t ou tard sous le poids de sa propre Ă©conomie (art de gĂ©rer le domus, la maison — Ă©conomie) : le système commence Ă coĂ»ter plus qu'il ne rapporte; sa flexibilitĂ© est mise en cause.
Éliminer les impulsions, les nettoyer est une tĂ¢che parfaitement cruciale. On utilisera avec bonheur le principe des 5S de Lean, adaptĂ© Ă la situation Ă laquelle on fait face, en l'occurrence la maintenance du système d'information digital. Voici une vidĂ©o d'introduction très gĂ©nĂ©rale du principe des 5S. Comme Ă©voquĂ© ci-avant, le fait de disposer de son propre système de monitoring et de sa propre comptabilitĂ© analytique garantit de pouvoir gĂ©nĂ©rer automatiquement … des impulsions sensitives (ou sensorielles) concernant celles qui sont de toute Ă©vidence sous-utilisĂ©es de telle sorte qu'elles puissent Ăªtre dĂ©tectĂ©es et proposĂ©es comme candidates Ă grooming. Tout ce qui peut Ăªtre automatisĂ© sans sacrifice de fonctionnalitĂ© ou de qualitĂ© doit l'Ăªtre.
UAD —
Un système d'information digital, une moelle épinière digitale, s'accompagne d'une gestion d'identités stricte et rigoureuse mais également centrale et unique. Une gestion impitoyable est impérative. L'absence de gestion ordonnée des droits d'accès, en ce y compris tous les processus d'entreprise qui l'accompagnent, est la première cause de déstabilisation de la moelle épinière qu'on vient de mettre en place, une source de l'augmentation des coûts qui se soustraient de la sorte à toute maîtrise.
Capteurs
Pour que l'entreprise puisse connaĂ®tre son Ă©tat gĂ©nĂ©ral il est indispensable qu'elle place des capteurs d'Ă©tat de ses organes (dĂ©partements) et aussi sur sa capacitĂ© Ă entrer en communication avec l'extĂ©rieur. Les senseurs doivent Ăªtre placĂ©s en prioritĂ© aux organes les plus sensibles pour l'organisation : un hĂ´pital n'est pas une maison de repos et une maison de repos n'est pas une banque qui, elle-mĂªme, n'est pas une compagnie de streaming.
Les impulsions sensitives doivent non seulement vous permettre de vous faire une idĂ©e prĂ©cise de votre propre Ă©tat mais Ă©galement de l'Ă©tat des autres organismes qui font partie de votre Ă©cosystème, vos fournisseurs en particulier mais encore vos concurrents ou tous autres organismes auxquels vous Ăªtes sensibles. C'est particulièrement le cas oĂ¹ vous auriez entamĂ© une transformation digitale oĂ¹ vous intĂ©grez les chaĂ®nes de valeur upstream et/ou downstream (voir chaĂ®ne de valeur).
Mission Critical
Une colonne vertĂ©brale digitale est un Ă©lĂ©ment de la chaĂ®ne Mission Critical. C'est en cela qu'il est nĂ©cessaire d'en faire un système rĂ©flexif, robuste et redondant quelles que soient les solutions techniques que vous mettrez en oeuvre (failover, load balancing, sondes nagios, …).
Scalability (évolutivité)
Scalability (Ă©volutivitĂ©) est la propriĂ©tĂ© d'un système permettant de gĂ©rer une quantitĂ© croissante de travail en ajoutant des ressources (machines, puissance CPU, mĂ©moire, …) ou en multipliant le parallĂ©lisme non-bloquant (multiplication des instances capables d'effectuer un travail parallèle)
Reliability (Fiabilité)
La fiabilitĂ© est un attribut de tout composant informatique (logiciel, matĂ©riel, rĂ©seau, … ) qui fonctionne constamment selon ses spĂ©cifications.
Robustesse / Redondance
La robustesse est la capacité d'un système à faire face aux erreurs et de pouvoir continuer à fonctionner, soit en isolant les erreurs dans les traiter, soit en les corrigeant.
On pourrait penser que la correction d'erreurs est la stratégie le plus intelligente et donc celle qui est recommandable. Il n'en est rien. En pharmacie, par exemple, il est interdit de corriger des erreurs car une correction est assimilée à une interprétation or toute interprétation est porteuse d'un degré d'incertitude ce qui est incompatible avec la nécessité d'avoir une connaissance parfaite (100% de certitude).
La stratĂ©gie Ă appliquer est affaire de contexte ; elle peut Ăªtre diffĂ©rente de worker en worker meme au sein d'un mĂªme sous-système.
Le système nerveux digital doit comporter sa propre redondance car, endommagĂ©, il risque redondance de paralyser l'ensemble de l'organisation, et ce, de manière plus sĂ©rieuse qu'il est dĂ©veloppĂ© et rĂ©pandu. Ă€ titre d'exemple de ce que nous pourrions appeler une forme de redondance je mets en avant la multiplication dĂ»ment contrĂ´lĂ©e des vecteurs de Cloud : vous avez dĂ©cidĂ© de passer par un fournisseur A, mais vous pouvez passer par un fournisseur B au cas oĂ¹ le fournisseur A vous fait dĂ©faut (ce qui est d'ailleurs une bonne façon de vous protĂ©ger d'un risque "fournisseur").
Failover
Il n'est pas raisonnable de tester un système de failover seulement au moment d'une panne rĂ©elle. Pas plus qu'il n'est raisonnable de tester votre système de Load Balancing de la mĂªme manière. Ces mĂ©canismes doivent Ăªtre testĂ©s rĂ©gulièrement, sur tous les environnements oĂ¹ ils sont en application ET en production. Je rĂ©pète : EN PRODUCTION !
Par ailleurs, il est Ă noter qu'en vertu du principe de fiabilitĂ©, il va de soi que le système de switching (passer d'une instance Ă l'autre, pour du failover ou pour des questions de charge) doit lui-mĂªme faire l'objet de tests. Je me suis dĂ©jĂ trouvĂ© en situation oĂ¹ nous faisions face Ă un problème parce que … le système de switching du composant qui Ă©tait censĂ© nous protĂ©ger d'une quelconque coupure provoquait lui-mĂªme la dĂ©faillance ! Qu'il s'agisse donc de failover ou de load balancing, ce(s) composant(s) doi(ven)t Ăªtre plus fiable(s) que les Ă©lĂ©ments qu'il gère. Si ce n'Ă©tait pas le cas, on ne ferait qu'augmenter la complexitĂ© du système en augmentant le nombre de points possibles de dĂ©faillance.
Mode dégradé
Le système nerveux digital doit pouvoir fonctionner en mode dégradé comme le suggère l'avionique moderne. Si l'avion est touché, il peut faire face à des pannes localisées mais il doit pouvoir continuer à voler. Une panne d'électricité ou d'Internet, pour avoir un impact sévère, ne peut néanmoins pas provoquer la faillite de l'entreprise. Le tout digital ne peut se concevoir qu'avec une roue de secours bien matérielle.
Outre ces éléments qui sont décrits ci-dessous succinctement, il est d'usage de pouvoir disposer de traces/logs utiles et d'une gestion des erreurs/exceptions limpides.
Traces / Logs / Erreurs / Exceptions
Je ne dirai que peu de choses des traces à enregistrer dans les fichiers de log. Le système de traces, quel que soit l'outil que vous utilisiez doit répondre aux exigences suivantes :
- avoir un degré de verbosité variable (plus ou moins de traces), si possible dynamique (application à chaud),
- Ăªtre central, pour l'ensemble du système et pour chaque sous-système qu'il contient,
- doit permettre de déterminer le parcours complet du message de l'entrée du système à sa sortie (considérant que la Dead Letter ou une station MRS sont des zones de parkage assimilées à des sorties pour ce sujet); cette remarque vaut particulièrement en cas de load balancing,
- doit Ăªtre interrogeable (queryable), visualisable et traitable de manière automatique (idĂ©alement par API)
- doit Ăªtre connectĂ© au système cardio, quel qu'il soit (interrogeable par le cardio)
- le système de traces doit faire l'objet d'un audit trail (pas d'ajout, pas de modification, pas d'effacement sans que ces changements soient détectables)
- le système de traces doit respecter GDPR
- le système de traces doit Ăªtre auto-archivable
- les traces enregistrĂ©es doivent Ăªtre les plus claires et comprĂ©hensibles possible : pas de message technique incomprĂ©hensible ou alors toujours flanquĂ© d'une explication destinĂ©e Ă Ăªtre lue par un humain,
- chaque problème doit, dans la mesure du possible, Ăªtre accompagnĂ© d'une suggestion de solution ou de contournement,
- toutes les exceptions doivent Ăªtre capturĂ©es et descendues dans les
traces : un exception de type
null pointern'est pas envisageable.
Infos
Vous pouvez bien Ă©videmment dĂ©cider des informations Ă stocker au mieux de vos intĂ©rĂªts et selon les habitudes des projets (quoi, oĂ¹, comment, quand). Voici nĂ©anmoins une liste d'Ă©lĂ©ments habituels :
- Datetime : date et heure de la trace (en mode UTC, surtout si vous avez affaire avec des parties se trouvant sur des réseaux différents)
- Niveau de trace : un nombre qui plus il est grand, plus il donne de détails. Je mets ce nombre en rapport avec le niveau de tracing général. À titre d'exemple : 0 = pas de trace (mais alors vous n'avez rien dans le fichier de log), 16 = niveau erreur, 32 = niveau warning, 64 = niveau info et ensuite … de plus en plus verbeux
- User ID : quelque chose qui vous permette d'identifier la personne concernée si applicable …
- Originator ID : une propriété qui identifie de manière unique le Message Worker qui a loggué la trace
- RequestedBy ID : une propriété qui identifie de manière unique la partie qui a initié la toute première demande
- Path : La route parcourue avant la trace
- Host : L'identification de l'environnement impliqué
- Error Code : le n° d'erreur concernĂ©. Par exemple le n° d'erreur MQSeries, ou Oracle, ou … Mais attention, tous ces numĂ©ros d'erreur peuvent se chevaucher et dès lors vous devrez trouver un mĂ©canisme qui permette de clairement distinguer l'origine de l'erreur. Pour X-Stream nous nous sommes servis des codes d'erreur utilisĂ©s par chaque vendor ; nous avons rĂ©servĂ© des plages de n° de codes pour MQSeries, pour Oracle, pour DB2, … et on appliquait une base de dĂ©marrage (ex. tous les codes d'erreur MQSeries Ă©taient dans la tranche 1000000 Ă 2000000 oĂ¹ 1000000 Ă©tait la base de dĂ©marrage Ă laquelle on additionnait simplement le code d'erreur de MQSeries). Cela nous permettait de retomber sur nos pattes aisĂ©ment (correspondance facile entre notre code d'erreur et le code d'erreur natif de MQSeries)
- What : type d'opération impliqué dans la trace
- Desc : une brève description de l'entrée de log
- AdditionalDetails : des éléments secondaires de l'entrée de log (valeur de certains paramètres, etc.)
Pour X-Stream nous avions l'habitude de penser de la manière suivante :
Si les informations disponibles en fichier de log ne nous permettaient pas de dĂ©terminer prĂ©cisĂ©ment la cause de l'erreur en moins de 5 minutes, c'est que le fichier de log Ă©tait mal foutu! En plus de 30 ans de carrière, c'est en ces termes que je rĂ©flĂ©chis Ă tout système de traces ! Cette mesure de 5 minutes Ă©tait vraiment un seuil concret de la mesure de l'efficacitĂ© des traces gĂ©nĂ©rĂ©es. Si on dĂ©passait ce seuil, cela voulait dire que la trace devait Ăªtre amĂ©liorĂ©e. Toute trace qui devait Ăªtre amĂ©liorĂ©e recevait la plus haute prioritĂ© dans le travail Ă accomplir par l'Ă©quipe. Cela a contribuĂ© de manière positive Ă la productivitĂ© de l'Ă©quipe. En outre, le bien-Ăªtre des membres de l'Ă©quipe s'en trouvait grandemant amĂ©liorĂ© : personne n'avait le moindre problème Ă accepter de prendre le beeper du support !
Chapitre Disaster Recovery
Que faire si l'ensemble du système email est down ? Quel impact sur le support ? Quel impact sur les divers services qui utilisent l'email pour envoyer des notifications ou pour recevoir des messages ? Que faire si le DNS dĂ©conne ? Quel impact si l'Active Directory est down ? Que se passe-t-il en cas de coupure d'Ă©lectricitĂ© ? Que faire si des certificats sont dĂ©passĂ©s ou rĂ©voquĂ©s ? Que faire si la connexion vers votre ISP vous lĂ¢che ? Que se passe-t-il si une licence n'a pas Ă©tĂ© renouvelĂ©e parce que quelqu'un a oubliĂ© de payer une facture ?
Vous Ăªtres en prĂ©sence d'un système critique ! Votre ESB s'arrĂªte, c'est la colonne vertĂ©brale qui cesse de fonctionner. C'est toute votre organisation qui s'arrĂªte ! Pensez-y !
Les dĂ©faillances ne se planifient pas, elles s'anticipent ; elles ne suivent aucune règle sauf celle de faire le plus de dĂ©gĂ¢ts possibles. Elles ont comme une volontĂ© du malin Ă s'invoquer en sĂ©rie, que l'une cause l'autre. N'attendez aucune indulgence de leur part !
En d'autres mots, cela se passe toujours plus mal que ce à quoi vous vous attendiez et il est simplement impossible de prévoir tous les cas : le manuel serait plus imposant que le livre de Proust, À la recherche du temps perdu[5] , titre fabuleusement prémonitoire.
Il reste alors à vous entraîner à faire face à l'inconnu et d'apprendre à l'apprivoiser car vous ne pouvez pas écrire tout ce qui pourrait mal tourner et, pour chaque cas de figure, disposer de la réponse du manuel.
Ce que vous pouvez faire en revanche c'est d'exceller dans la dĂ©tection et la rĂ©action. La dĂ©tection doit intervenir très tĂ´t ; la rĂ©action doit Ăªtre la plus prompte possible. Au fond, c'est une question de rapiditĂ©. Cela, oui, ça fonctionne quel que soit le problème.
Dans X-Stream par exemple, Gregory Sovaridis et moi-mĂªme, avons Ă©tĂ© confrontĂ©s Ă un de ces types de problèmes. Un composant essentiel de notre système lĂ¢chait de manière alĂ©atoire. Tous les autres composants continuaient Ă faire leur boulot sauf celui-lĂ qui se mettait dans un Ă©tat zombie : ce worker Ă©tait toujours vivant mais il ne faisait plus rien. Vu de l'extĂ©rieur, l'ensemble du système semblait continuer de fonctionner mais Greg et moi savions que quelque chose se passait mal grĂ¢ce Ă une dĂ©tection prĂ©cose et prĂ©cise. Nous avons alors eu un petit conciliabule qui nous a d'ailleurs amenĂ©s Ă tĂ©lĂ©phoner en Belgique pour faire part du problème et Ă demander une autorisation. En clair, nous souhaitions obtenir l'autorisation de mettre en place une solution un peu ... spĂ©ciale : il s'agissait de "tuer" l'application fautive rĂ©gulièrement (mĂªme si elle ne prĂ©sentait pas de problème) et d'en redĂ©marrer une instance aussitĂ´t. Notre Account Manager a voulu s'assurer que nous serions capables d'effectuer cette opĂ©ration directement sur l'environnement de production de la banque italienne oĂ¹ notre système Ă©tait dĂ©ployĂ©. C'Ă©tait bien normal. Mais au fond, nous n'avions pas d'autre choix, en tout cas, on n'en voyait pas d'autre.
Nous avons donc crĂ©Ă© sur place un nouveau composant que nous avons appelĂ© le "Revivor" dont la tĂ¢che Ă©tait de tuer un processus et d'en lancer une nouvelle instance.
Revenus à Bruxelles, et forts de cette réussite de terrain, nous avons généralisé le concept pour en faire un composant standard de la suite X-Stream.
La dĂ©tection des problèmes se faisait bien AVANT toute manifestation de panne grĂ¢ce Ă notre composant Cardio lequel envoyait un message de service au Revivor dont la mission Ă©tait de "tuer" un processus prĂ©cis (celui oĂ¹ la panne Ă©tait dĂ©tectĂ© cette fois-ci, et non plus de tuer un processus qui fonctionnait) et d'en redĂ©marrer une nouvelle instance aussitĂ´t. In fine, grĂ¢ce au Revivor le système, dans sa globalitĂ©, continuait Ă remplir sa fonction sans dĂ©faillance.
De ceci il faut dégager une conclusion générale :
Trouver une solution ce n'est pas toujours résoudre un
problème, c'est parfois accepter le problème mais l'empĂªcher d'avoir un
impact.
Une autre conclusion s'impose, humaine celle-lĂ : le Revivor avait
contribué à augmenter de manière significative notre tranquillité
d'esprit, notre apaisement, notre sĂ©rĂ©nitĂ© mĂªme. Cela n'Ă©tait pas
le moindre des bénéfices.
Types d'impulsions
Impulsions exécutoires
Il s'agit d'impulsions d'exécution comme celles qui parcourent les nerfs moteur de l'anatomie humaine, le cerveau qui envoie une impulsion à la main gauche pour qu'elle saisisse un objet par exemple. Dans le cas d'un système nerveux digital il pourrait s'agir de l'envoi d'un mail, ou de la fabrication et stockage d'un document. On exécute une fonction.
Messages de service
Il s'agit d'impulsions exĂ©cutoires destinĂ©es Ă des applications. Cette dĂ©nomination a Ă©tĂ© proposĂ©e par Jean Bourdin dans le cadre de projets bancaires (Intesa — 2001 et 2002, UBS — 2002 et 2003, Banca di Roma — 2004, …). Quelques exemples de messages de service :
- Rechargement du fichier de configuration
- Start / Stop processing
- Spawn et kill de processus
- Heartbeat
- Rechargement de la gestion des erreurs et exceptions
- Routage des erreurs et exceptions
- Niveau de sévérité des erreurs et exceptions (errorlevel)
- Réassignation de ou des files d'entrée (queues)
- Type de lecture (destructive ou non — consommation des messages)
- Utilisation de routages alternatifs (gestion de l'encombrement, …)
- …
Impulsions sensitives (ou sensorielles)
Ce sont les impulsions qui véhiculent les informations qui proviennent des senseurs, internes pour la plupart, mais également externes.
Il est très habituel de lancer une impulsion de type heartbeat entre deux points nodaux de la colonne digitale afin de pouvoir dĂ©terminer si, sur le segment visĂ©, la transmission des impulsions est toujours possible (coupure, engorgement, … ).
Impulsions ministérielles
J'ai choisi le terme "ministĂ©rielle" par Ă©gard Ă son Ă©tymologie : ministre … celui qui accomplit une tĂ¢che au service de quelqu'un.
Une impulsion ministĂ©rielle est une impulsion double se composant d'une requĂªte et d'une rĂ©ponse, l'exercice d'un service au sens gĂ©nĂ©rique mais aussi au sens entendu en informatique (service et microservice).
Les connexions externes (Outside World)
La colonne vertĂ©brale digitale a pour ambition — et je le rĂ©pète car ceci est vraiment d'une importance capitale — de connecter tous les organes internes de l'entreprise (achats, ventes, ressources humaines, comptabilitĂ©, IT, audit, dĂ©partement juridique, marketing, …) mais Ă©galement de connecter l'entreprise Ă son Ă©cosystème et plus particulièrement, mais pas uniquement, aux chaĂ®nes de valeur en amont (les fournisseurs, …) et en aval (clients, distributeurs, prescripteurs, consommateurs, …). C'est en cela qu'on se connecte au monde extĂ©rieur.
Un dĂ©faut assez habituel de la mise en place d'une colonne vertĂ©brale digitale, ou d'un ESB connectĂ© sur l'extĂ©rieur, consiste Ă se baser sur l'hypothèse selon laquelle les autres systèmes avec lesquels l'organisation collabore sont fiables, disponibles et rĂ©actifs Ă tout moment. Le système doit accepter le fait que les systèmes tiers peuvent ne pas Ăªtre disponibles ou rĂ©actifs Ă certains moments et doit Ă©tablir des tolĂ©rances pour de tels Ă©vĂ©nements (voir les parties robustesse et mode dĂ©gradĂ©).
Architecture Ă base de files d'attente (Queue-based System Architecture)
L'architecture basée sur des files d'attente (QBSA) est un excellent moyen de construire des systèmes qui nécessitent la collaboration de plusieurs systèmes distribués connectés vers l'extérieur.
La plupart des traitements dans un système basĂ© sur des files d'attente sont pris en charge de manière asynchrone par des processus autonomes souvent conçus comme des … services (input et output par file d'attente).
Chaque file d'attente constitue un noeud du système, un noeud qu'il est facile de monitorer et qui fournit un moyen aisĂ© de montĂ©e en puissance (plusieurs instances d'un mĂªme processus connectĂ© Ă une mĂªme file d'attente par exemple), moyen que nous avons utilisĂ© chez Viveo pour atteindre des performances extrĂªmes dans le cas d'un système de Compliance Filter mis en place chez UBS (Zurich) et qui permettait ainsi de traiter des millions de messages SWIFT avant le cut-off time journalier.
Notons enfin qu'un ESB basé totalement ou partiellement sur des files d'attente permet de créer des zones de temporisation à l'envi, ce qui permet de réguler aisément le trafic de la colonne vertébrale digitale, voire de le contrôler manuellement ou automatiquement, ce que nous avions d'ailleurs réalisé chez Viveo avec X-Stream [6] , un EAI financier, labellisé Gold par SWIFT : le composant Cardio permettait ainsi le contrôle et la régulation de l'ensemble du système EAI.
On voit donc qu'un système QBSA s'intègre naturellement dans la mise en Å“uvre d'un bus de services d'entreprise (ESB) : l'ESB peut fonctionner entièrement ou partiellement sur ce paradigme.
Vue générale
Un système QBSA est fondamentalement un système de routage et comme tout système de routage il comporte un chemin Ă prendre, des dĂ©cisions plus ou moins intelligentes concernant les chemins Ă prendre (aller vers A, aller vers B, aller vers C, … par combinaison de «et» et «ou»), et … les chemins effectivement pris (les dĂ©tournements sont possibles dans des systèmes intelligents).
Message Broker
Le Message Broker (agent de messages) lit les messages envoyés à un système afin de les valider, le cas échéant de les transformer, et de les rediriger.
Il permet de découpler efficacement émission, transformation, réception et traitement.
Le système peut avoir plusieurs entrĂ©es possibles au rang desquelles, bien sĂ»r, une file d'attente d'entrĂ©e (System Input Queue). Mais le système peut aussi proposer autant de types d'entrĂ©es qu'il lui est possible de supporter : FTP, UDP, emails, notifications, … Tout cela sera gĂ©rĂ© par ce composant particulier qui s'appelle le Message Broker et qui alimente ses Workers, ces points de traitement qui font la richesse du système mais aussi sa raison d'Ăªtre.
(Message) Worker
On parle souvent d'un Worker, ce qui comme le nom l'indique est un noeud qui traite un message, c'est-à -dire qui lui applique le traitement attendu. Le Message Processor est constitué d'une file d'attente d'entrée et d'un Worker qui s'occupe du traitement proprement dit. Je fais la simplification de parler indistinctement de Message Processor et de Worker tout en favorisant la seconde formulation.
Le worker est donc un processus qui rĂ©alise le traitement qui est attendu de lui. Un Worker lit sa file d'attente d'entrĂ©e, effectue son travail, et retourne le rĂ©sultat lĂ oĂ¹ il est attendu, ce qui, la plupart du temps, est une destination qui ne lui est pas connue (c'est le routage qui lui dicte oĂ¹ le message doit Ăªtre envoyĂ©). Si une erreur survient, il dĂ©lègue le message Ă sa propre Dead Letter ou Ă celle de l'ensemble du système (qui peut d'ailleurs avoir plusieurs files qui jouent ce rĂ´le).
Quant Ă pouvoir juger de l'ampleur du travail qui est Ă faire par le worker, il s'agit lĂ d'un Ă©quilibre entre performance et gestion du système : plus le travail Ă rĂ©aliser est ambitieux et lourd, plus on risque un encombrement. Plus on rĂ©duit le travail Ă faire par 1 worker spĂ©cifique, plus on multiplie les workers, plus la gestion devient complexe et plus le lead-time de traitement end-to-end en pĂ¢tit. En ces circonstances particulières, la multiplication des instances du worker renforce les possibilitĂ©s de scale out.
Chaque Worker doit posséder une identité unique et spécifique : nom et
version, etc. On utilisera avec bonheur le schéma
SoftwareApplication totalement documenté que nous fournissent
Google, Yahoo, Yandex et Microsoft : SoftwareApplication. Ce
schéma, par héritage, dérive et complète les deux autres schémas suivants :
CreativeWork et Thing. Vous trouverez ces trois classes
documentées en PHP : SoftwareApplication, CreativeWork et
Thing. J'espère que cela vous sera utile. Au travers de ces 3 schémas
qui sont aujourd'hui des standards de l'industrie vous disposez de toutes
les propriétés qui permettent d'identifier sans doute possible tous les
Message Workers de votre colonne digitale, qu'ils soient conçus par vos
soins ou pas.
Versionnage de message
Tout comme il est recommandé de versionner des services, il est fortement recommander de versionner les messages. Comme un service, un message a une forme de signature qui est son contrat. La version du message fait partie de ce contrat.
GrĂ¢ce au schĂ©ma SoftwareApplication et de ceux dont il dĂ©pend vous avez tout ce qui est nĂ©cessaire pour attribuer une version Ă un message [7] . Si toutefois un message n'Ă©tait pas versionnĂ©, il est d'usage de lui appliquer le traitement rĂ©servĂ© Ă la dernière version dudit message.
Routage
Il est particulièrement mal avisĂ© d'implĂ©menter la logique de routage au sein de chaque Message Worker. Celui-ci doit Ăªtre agnostique, sauf exception, par rapport aux routes Ă emprunter. Il suffit de penser Ă une colonne vertĂ©brale digitale corpulente pour se rendre compte qu'effectivement il ne semble pas idoine de laisser le routage aux soins des workers. Par l'absurde, on n'imagine pas de devoir modifier le routage auprès de chaque worker.
L'ensemble du système doit disposer de dĂ©cisions centrales considĂ©rĂ©es comme Ă©tant la Business Logic de routage. Ces dĂ©cisions doivent Ăªtre formulĂ©es de manière suffisamment simples pour pouvoir Ăªtre modifiĂ©es aisĂ©ment sans nĂ©cessiter le moindre changement au sein des Message Workers, idĂ©alement directement par le Business car il va de soi que si la Transformation Digitale invoque de nouveaux processus au sein de sa cellule d'innovation, il faudra potentiellement adapter le routage. Il faut s'y prĂ©paper.
Aller vers A ou vers B, aller vers A et vers B
En matière de routage, aller vers A, aller vers B, aller vers C, … par combinaison de «et» et «ou» cela signifie que des messages peuvent Ăªtre dirigĂ©s vers un Message Worker ou un autre mais aussi vers l'un ET l'autre. On assiste alors une forme de duplication de messages dans le système. On parle souvent de Y-copy.
Cette technique de Y-copy est excessivement puissante car elle dote les impulsions d'un don d'ubiquité qui permet un haut parallélisme de traitement.
Si les chemins parallèles sont appelĂ©s Ă devoir Ăªtre rĂ©conciliĂ©s, il faudra prĂ©voir un mĂ©canisme qui le permette (les rĂ©sultats obtenus sur un chemin de traitement doivent Ăªtre consolidĂ©s avec les rĂ©sultats obtenus sur un autre chemin). Si les chemins sont indĂ©pendants, … il n'y a rien Ă faire.
Systèmes logiques
Une colonne digitale doit apprendre à composer avec des éléments épars ou assemblés logiquement : des sous-systèmes.
Deux philosophies s'opposent :
- Concevoir un système avec un Message Broker central qui dispatche lui-mĂªme les messages vers les diffĂ©rents sous- systèmes ou …
- Concevoir un système avec autant de Message Brokers qu'il y a de sous-systèmes.
J'ai trouvĂ© autant d'avantages Ă l'une ou l'autre des conceptions. J'avoue cependant avoir un faible pour la solution hybride qui utilise un Message Broker central ET autant de Message Brokers qu'il y a de sous-systèmes. Au rang des facilitĂ©s qui ont emportĂ© ma dĂ©cision on trouve la facilitĂ© gĂ©nĂ©rale qui permet de contrĂ´ler l'ensemble du système au travers d'une seule Input Queue centrale MAIS de pouvoir contrĂ´ler chaque sous-système indĂ©pendemment Ă©galement ce qui s'avère Ăªtre un avantage non nĂ©gligeable pour des opĂ©rations de maintenance.
Je conseille Ă©galement d'avoir un outil de composition de messages (Composer dans le schĂ©ma) et un outil de lecture des messages (Reader) par sous-système. Cela permet a des Ă©quipes entièrement indĂ©pendantes de travailler simultanĂ©ment sans se gĂªner.
Il n'est pas idiot de disposer d'un système de monitoring et de contrĂ´le par sous-système (Cardio dans le schĂ©ma) mĂªme si ce n'est pas ce qu'illustre le diagramme ci-dessus. En tout Ă©tat de cause, il vous est nĂ©cessaire de disposer d'au moins une instance de cardio pour l'ensemble du système (au moins une !)
Chaque sous-système peut avoir sa propre Dead Letter. Vous pouvez aussi décider de mettre en place une Dead Letter qui inhérente au système dans son ensemble.
Services et Messages
La colonne vertĂ©brale digitale n'est rien de plus qu'un système d'impulsions lesquelles sont interprĂ©tĂ©es de manière diffĂ©rente par les organes qui les rĂ©ceptionnent. Que ces impulsions soient des appels et des rĂ©ponses de services ne change rien Ă l'affaire. Tout se passe comme si deux espèces diffĂ©rentes cohabitaient en coopĂ©rant ou en Ă©voluant de manière indĂ©pendante : les services et les messages. Rien n'empĂªche les Message Workers de faire appel Ă des services et rien n'empĂªche les services d'envoyer des messages.
Cette absence de dĂ©marcation entre messages et services est ce qui fait la force d'un système mais c'est aussi ce qui en fait sa complexitĂ© et donc son degrĂ© d'entropie. Plus les deux s'imbriquent, plus la variation des Ă©tats augmente, plus les interdĂ©pendances augmentent, plus les degrĂ©s de libertĂ© croissent, plus la propagation des difficultĂ©s doit Ăªtre tenue sous contrĂ´le et surveillĂ©e. Ce n'est pas une mince affaire. Cela demande de la maturitĂ©.
Nommage et environnements
J'ai trouvé utile de disposer d'une forme de dictionnaire qui permette de
nommer les objets selon une logique qui m'Ă©tait propre, facilement
compréhensible. Par exemple, si vous avez un sous-système comptable dans votre
ESB (ensemble applicatif comptable), vous pouvez décider d'appeler la file
d'attente de ce sous-système ACCOUNTING_INPUT_QUEUE alors que
l'ensemble du système (tous sous-systèmes inclus) pourrait avoir une file
d'attente d'entrée nommée SYSTEM_INPUT_QUEUE.
Par contre, il se pourrait que les équipes systèmes ou infra vous imposent
une sorte de nomenclature spécifique et il se peut aussi que cette nomenclature
n'Ă©voque aucune logique pour vous. Que dire des files d'attente
TEST_NATION_S_202010_MAIN_V4_INPUT et
TEST_NATION_S_202010_ACC_V4_INPUT ? Il y a fort Ă parier que ces
noms seront, pour vous, beaucoup moins parlants.
Ayant travaillé pour de multiples clients aux multiples nomenclatures
différentes, avec parfois des nomenclatures spécifiques aux environnements sur
lesquels la solution était déployée, j'ai trouvé facile de disposer d'un
dictionnaire, modifiable par le client, qui transformait les noms d'objets
logiques en noms physiques (e.g. ACCOUNTING_INPUT_QUEUE en
TEST_NATION_S_202010_ACC_V4_INPUT). Au-delĂ , cela facilite
grandement la documentation du système !
Un simple fichier XML fait merveille. Facile Ă Ă©diter, aisĂ©ment transportable d'environnement Ă environnement, dĂ©ployable Ă souhait …
Mesure de la performance
Lorsque Gregory Sovaridis et moi-mĂªme avons conçu X-Stream NT, nous Ă©tions face Ă un double problème : (1) bĂ¢tir un système qui fonctionnellement filtrait les bons messages de paiement des mauvais le plus efficacement possible et (2) Ăªtre capable de traiter 1,6 millions de messages quotidiennement. Une double contrainte oĂ¹ lorsque le premier dĂ©fi Ă©tait le mieux rempli, il prenait aussi le plus de temps.
La performance Ă©tait au cÅ“ur de notre dĂ©veloppement, prĂ©sente Ă
tout moment. Nous avons été obligés de revoir de fond en comble un
ensemble d'algorithmes, l'utilisation des librairies (libxml par exemple),
etc. Dans nos premiers essais, nous nous sommes rendus compte que nous ne
pouvions pas nous permettre d'encoder le payload des messages en base 64 car
le seul décodage ne permettait pas d'atteindre la performance requise pour
traiter autant de messages. Nous avons dès lors inventé notre propre
algorithme d'encodage (inspiré d'une discussion avec le collègue Koen
Hufkens), ré-écrit un un parser XML maison basé sur une implémentation
personnelle d'une forme réduite de RegEx (fonction STR_Like(),
Ă©crite partiellement en C et partiellement en assembleur et que j'avais
publiée dans le magazine Point DBF une dizaine d'années plus tôt). Nous
avons réécrit le fonction strstr() du langage C car on ne le
trouvait pas assez rapide et lui avons substitué un autre fonction basée sur
l'algorithme Boyer-Moore à alphabet réduit, etc. Bref, la performance était
présente dans tous nos développements; il n'était pas une ligne de code que
nous Ă©crivions qui y Ă©chappait.
Une telle attention ne peut que s'accompagner de tests systématiques. Nous lancions donc de nombreuses vérifications qui, au fur et à mesure de notre développement nous confortaient qu'on tiendrait le seuil de performance en-deça duquel notre solution eut été rejetée par le client, la très puissante UBS.
En fait, dès qu'une partie nouvelle était développée, celle-ci faisait l'objet d'un test de performance.
Un jour nous avons notĂ©, incrĂ©dules, une forte baisse de la performance. Nous n'avons pas mis longtemps Ă dĂ©couvrir le coupable : le passage par valeur d'une large structure au lieu d'Ăªtre passĂ©e par rĂ©fĂ©rence … soit un oubli d'un seul byte (&).
Ce que rĂ©vèle cette petite digression c'est la chose suivante : des tests de performance, cela se fait tout au long du dĂ©veloppement, from day one. Si ces tests n'avaient pas Ă©tĂ© frĂ©quents dans le dĂ©veloppement de X- Stream NT, jamais nous n'aurions Ă©tĂ© capables de dĂ©terminer si rapidement la cause de la dĂ©gradation de perf. C'est parce que nous n'avions que peu de code modifiĂ© Ă scruter que nous avons Ă©tĂ© prompts Ă trouver le problème et Ă trouver la solution, le fameux &. Je vous invite ainsi Ă planifier rĂ©gulièrement des tests LSP — Load, Stress and Performance — dans la mise au point de votre colonne vertĂ©brale digitale car, oui, elle doit Ăªtre la plus rapide possible.
Un processus progressif
La mise au point de la colonne vertĂ©brale ne se fait pas en chambre. Elle se fait sur le terrain … dans le corps mĂªme de l'organisation, par petites Ă©tapes successives. C'est une forme progressive de sĂ©crĂ©tion de tissus, une embryogenèse. Ă€ ce titre cette formation connaĂ®t plusieurs Ă©tapes, chacune avec ses points d'attention propre.
Tout commence par la fibre nerveuse par laquelle les impulsions peuvent Ăªtre transmises. Sans elle, l'idĂ©e d'impulsion n'existerait pas. On parle ici de l'ESB, la moelle Ă©pinière du système qui sĂ©crète les services comme le cerveau sĂ©crète la pensĂ©e.
Ensuite, les services font leur apparition gentiment forcés par les besoins de programmeurs. Je ne renie absolument pas le fait indiscutable que les services servent les objectifs de l'organisation, et donc partant, des objectifs Business. Il n'en reste pas moins vrai qu'ils naissent toujours sous l'impulsion des développeurs et architectes. Tout commence par un premier service et l'enjeu qui se joue est plus un enjeu de plomberie qu'autre chose : est-ce que l'impulsion arrive à se frayer un chemin, à aller d'un point à l'autre et à demeurer compréhensible.
À ce stade, le monitoring n'a guère d'importance, la sécurité non plus, la performance, la charge, le stress pas davantage. Ce ne sont tout simplement pas les points d'attention du moment et cela restera le cas pour quelques dizaines d'autres services dont la multiplication est infatigable.
Un effet de taille
Les services se multiplient et avec eux l'utilisation qu'on en fait qui prend des tournures parfois inattendues. On passe par des Ă©tapes oĂ¹ l'application de standards devient nĂ©cessaire, oĂ¹ le monitoring devient incontournable, oĂ¹ la sĂ©curitĂ© devient inĂ©vitable.
Suivre des dizaines, puis des centaines, et au final des milliers de services parfois répartis sur plusieurs fuseaux horaires devient l'enjeu premier.
Ă€ mesure que votre la colonne vertĂ©brale se dĂ©veloppe, Ă mesure que son utilisation se propage, vous devrez Ăªtre en mesure de surveiller de nombreux processus, plus que probablement rĂ©alisĂ©s par des Ă©quipes dissĂ©minĂ©es dans toute l'organisation. C'est un de ces moments oĂ¹ le bon Ă©tat des routes et l'Ă©tat gĂ©nĂ©ral du trafic vous intĂ©resseront plus que la petite impulsion qui est bloquĂ©e au fin fond d'une file d'attente. Vous en serez Ă surveiller l'Ă©tat de votre rĂ©seau ! Vous aurez besoin d'un composant Cardio. (Lien vers page Cardio).
Un effet boule de neige
Plus la colonne vertébrale se développe, plus elle sécrète de services, plus il y a de services et plus il est probable qu'ils se mettent à interagir les uns avec les autres, plus ils interagissent, plus ils s'imbriquent, plus ils s'imbriquent, plus ils se figent. C'est le danger de sclérose dont je parlais plus haut.
Les services se figent car leur modification entraĂ®ne des rĂ©sultats inattendus mĂªme si tout est fait pour Ă©viter les effets secondaires indĂ©sirables. Éviter les bugs devient illusoire. Modifier des services requiert un effort de synchronisation qui n'Ă©tait pas nĂ©cessaire quand les services Ă©taient peu nombreux. La question devient alors de savoir comment Ăªtre rĂ©silient et faire en sorte que l'inattendu ne bloque jamais le système. C'est le moment aussi oĂ¹ la multiplication des services ralentit, un moment qu'il faut dĂ©tecter sans s'inquiĂ©ter : sans ce phĂ©nomène, on aurait Ă faire face Ă un cancer, c'est-Ă -dire une multiplication anarchique dont l'horizon est l'effondrement de tout le système. C'est un moment dĂ©licat oĂ¹ les principes gĂ©nĂ©raux doivent l'emporter sur les règles particulières, un moment de diversitĂ© qu'il serait nuisible d'empĂªcher ou de contraindre. C'est un point critique de tout dĂ©veloppement ESB ().
Les end-points extérieurs
Ne cherchez pas ! Oui, vous allez utiliser des end-points extĂ©rieurs parce que vous allez utiliser des services extĂ©rieurs ! Vous pouvez vous en dĂ©fendre mais tout cela est affaire de progression. Vous ferez peut-Ăªtre appel des services exterieurs très rapidement ou peut-Ăªtre lentement, mais vous n'y couperez pas car telle est la nature de notre monde connectĂ© (et le Cloud n'y est pas Ă©tranger, bien Ă©videmement).
Ce site est en construction ! Son contenu évolue chaque jour. ICI, JE DEVRAIS INDIQUER QUE L'APPEL D'UN SERVICE EXTERIEUR DOIT AUSSI S'ACCOMPAGNER D'UNE FORME DE PROTECTION POUR SE PERMETTRE DES ROUTES ALTERNATIVES. EXEMPLE : FAIRE APPEL À UN SERVICE DE TRADUCTION POUR LEQUEL IL FAUT POUVOIR EFFECTEUR UN DISPATCHING VERS DIVERS FOUNRISSEURS DE SERVICE. IL DOIT ÉGALEMENT S'ACCOMPAGNER DU PRINCIPE DU CASHIER POUR PERMETTRE LA REFACTURATION INTERNE; IL FAUT EGALEMENT PRESENTER UNE FAÇADE COMMUNE QUEL QUE SOIT LE SERVICE EXTERNE APPELÉ.
To be continued
Invitation au chaos — Une note finale d'hérésie
NetFlix a inauguré un logiciel dont peu de responsables informatiques sont fans : le Chaos Monkey, un logiciel qui met la pagaille dans l'infrastructure, qui génère un sacré micmac. Une série de liens existent qui expliquent la justesse et l'efficacité du concept car, in fine, le Chaos Monkey se donne pour objectif d'améliorer considérablement la résilience d'un système et c'est ici ce qui m'importe puisqu'une colonne vertébrale digitale est mission critical.
Si le Chaos Monkey teste la résilience d'un système il teste également la résistance au stress des femmes et des hommes qui tout à coup font face à des problèmes imprévus, un test grandeur nature des hommes et des processus.
Un peu comme le développement TDD commence par écrire un test visant à vérifier un code qui n'existe pas encore, je vous invite à écrire un MicMacMaker qui perturbe votre colonne digitale qui n'a pas encore de file d'attente ou de endpoint. Faites le avec discernement et mesure, tourné vers un objectif résolument positif d'amélioration de votre colonne.
Notes de bas de page
[1] … Il n'est pas inexact de penser Ă©galement que le pilier Shorter Cycles puisse aussi s'envisager comme une contrainte
[2] … On ne parle pas ici de monitoring hardware; on parle de monitoring applicatif
[3] … GĂ©nĂ©ralement, la consommation de ce type de services se fait sur des modèles très similaires. On trouvera aussi de quoi s'exercer avec quantitĂ© d'autres services comme ceux de Deezer, Spotify, iTunes, Tomtom, Michelin, Text Razor, geonames, la banque carrefour, les services postaux, …
[4] … Quand les services se multiplient leur imbrication devient inĂ©vitable. Ce n'est pas la peine de l'empĂªcher; il s'agit plutĂ´t de l'accompagner
[5] … 9609000 caractères, près de 1,5 million de mots. Cet ouvrage dĂ©tient le record du plus long roman au Guinness
[6] … X-Stream Ă©tait un produit de type Enterprise Application Integration faisant partie d'une suite d'outils de type système expert / Intelligence Artificielle visant Ă normaliser et rĂ©parer des messages de paiement SWIFT. Le cÅ“ur d'X-Stream a Ă©tĂ© rĂ©alisĂ© en ANSI C montĂ© sur MQSeries, l'ancien nom de WebSphere MQ, IBM MQ, par Gregory Sovaridis et Patrick Boens. Le système, labellisĂ© Gold par SWIFT dès 2002, a Ă©tĂ© utilisĂ© dans de nombreux projets bancaires oĂ¹ la performance, la robustesse, la fiabilitĂ© et l'Ă©volutivitĂ© Ă©taient particulièrement exigentes. La suite X-Stream offrait un Message Broker (le SuperSwitch), un composant de contrĂ´le d'Ă©tat, de lancement de commandes et de rĂ©gulation (le Cardio), un compositeur de messages (le Composer) et une station de lecture (le Reader). Les composants Composer, Reader et Cardio, couplĂ©s Ă une station de rĂ©paration manuelle de messages — Manual Repair Station ou MRS, permettaient d'effectuer des tests entièrement automatisĂ©s en envoyant ± 400000 messages dans le système chaque vendredi (cĂ©rĂ©monie du dry-run) : l'arrivĂ©e desdits messages dans des files d'attente bien spĂ©cifiques garantissant le traitement correct des messages envoyĂ©s.
[7] … Vous pouvez aussi vous reposer sur la Gestion sĂ©mantique de version 2.0.0
[8] … La nature et le nombre de services augmente considearblement conforme au constat qui prĂ©cède et qui annonce le foisonnement des services. Jetez un oeil sur les services cognitifs de Microsoft, sur ceux de Google ou d'Amazon, etc. et vous vous rendrez bien vite compte que la tentation de faire appel Ă l'intelligence exterieure est tout bonnement indomptable


