19-01-2024 09:55:23
Introduction
La colonne vertébrale digitale est cette autoroute où passent les impulsions qui permettent aux différents organes de l'entreprise de se mettre en contact les uns avec les autres et d'échanger des informations (lato sensu, au sens large).
La colonne vertébrale est pour une organisation l'équivalent
d'un système nerveux responsable de la
coordination des actions avec l'environnement extérieur et de la communication
rapide entre les différentes parties du corps.
Rappel : Colonne vertébrale digitale
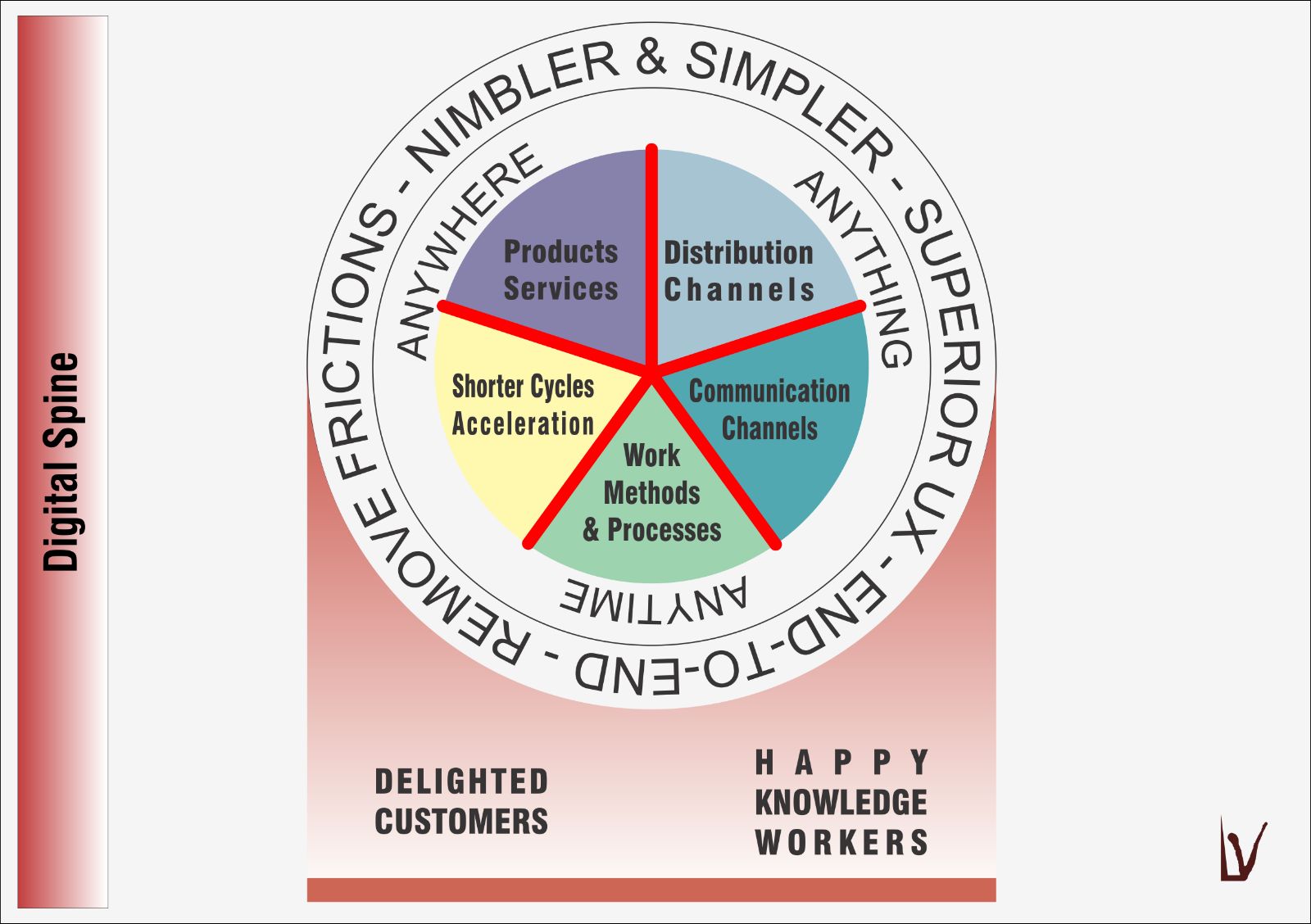
La colonne vertébrale est cette étoile qui apparaît dans le présent schéma.
Pour l'architecte d'entreprise, cete colonne vertébrale prend la forme d'un ESB (Enterprise Service Bus) (on parlera aussi de SOA — Service Oriented Architecture, d'EAI — Enterprise Application Integration, de QBSA — Queue-Based System Architecture, etc. tout cela dépendant du contexte dans lequel on évolue.
Or, cet ESB n'est que le rassemblement de sous-systèmes de l'organisation
(départements et domaines fonctionnels). Je parle d'organes et, comme dans
l'anatomie humaine, un organe est un ensemble de
tissus collaborant à une même fonction physiologique. Certains organes
assurent simultanément ou alternativement plusieurs fonctions, mais dans ce
cas, chaque fonction est généralement assurée par un sous-ensemble de
cellules.
Je représente cet ESB graphiquement de la manière suivante :
Une plongée au cÅ“ur de chaque sous-système nous fait nous rendre compte que chacun rencontre des problèmes communs , communs entre tous les organes de l'entreprise, mais aussi communs à la grande majorité des organismes qui composent l'écosystème de l'entreprise (le monde extérieur). Pour cela nous devons nous en remettre aux Enterprise Patterns. Quelques exemples : envoyer des mails, traduire des textes, accueillir un nouveau collaborateur, gérer les factures, gérer les commandes, enclencher un processus d'achat, aposer une signature digitale, …
Chaque sous-système, qu'il fasse appel aux Enterprise Patterns ou non, manipule des concepts communs : c'est quoi un client, c'est quoi un fournisseur, c'est quoi une personne physique, c'est quoi une personne morale, c'est quoi une facture, c'est quoi un compte bancaire, …
Pour que chaque partie puisse communiquer, il est nécessaire d'avoir un vocabulaire commun.
Vocabulaire commun
De nombreux répertoires fournissent des définitions toutes faites dont il est nécessaire que la Transformation Digitale s'empare afin d'harmoniser le vocabulaire de l'entreprise, à ka fois pour toute la communication qui a lieu en son sein mais également avec l'extérieur, avec son écosystème. Au- delà de ce bénéfice considérable, l'entreprise qui fait appel aux Enterprise Patterns et aux répertoires publics réalise des économies car l'effort de définition a été fait par autrui tout comme l'effort de maintenance.
2 répertoires incontournables
Bien qu'il existe de très nombreux répertoires, souvent spécialisés dans des domaines particuliers, je vais en introduire deux que je consulte régulièrement pour tout concept sur lequel je suis amené à travailler : Wikidata et Schema.org. Je les utilise de concert me servant ainsi de l'un ET de l'autre plutôt que de l'un OU de l'autre.
C'est quoi une facture ? Quelles sont les caractéristiques d'une facture ?
C'est quoi un article ? un article de presse ? un article technique ? un site web ? une page web ? une page de contact ? un garage ? une voiture ? une moto ? un avion ? un bateau ? un client ? un fournisseur ? et … une facture ? etc. Voilà des questions que les informaticiens du monde entier se posent ou se sont posées à un moment ou l'autre de leur carrière. Leurs réponses se trouvent cristallisées dans tous les logiciels du monde, parfois, malheureusement, de manière incohérente ce qui nuit gravement à l'efficacité de la colonne vertébrale. Les moyens existent cependant pour que ces incohérences soient effacées.
Schema.org
schema.org est une tentative de standardisation, une démarche de cohérence, une poursuite de convergence pour qu'au travers des programmes que nous manipulons tous les jours une compréhension commune puisse se dégager. Pour que lorsque nous parlions d'une facture, à Pékin, Bruxelles, New York ou Paris, on s'en fasse la même représentation : une description de ce qu'est une facture, les caractéristiques d'une facture, les types d'informations de chaque propriété, etc.
schema.org est une initiative de Google, Microsoft, Yahoo et Yandex, organisée sous forme de communauté ouverte qui se donne l'objectif d'établir des ontologies, du grec ὄντος (« étant ») et λόγος (« discours, parole, étude »), des ensembles structurés de termes et relations couvrant des concepts spécifiques dans des domaines particuliers.
Retournant à mon exemple de facture, il est évident que cet "objet" appartient à un domaine plus large, tout comme une "offre", un "bon de commande", "une note de crédit", un "paiement", etc. C'est ce domaine supérieur que couvre une ontologie.
Plus simplement, schema.org parlera de vocabulaires qui aident à comprendre le monde qui nous entoure. C'est quoi un produit ? un service ? une entreprise ? un hôpital ? un évènement ? un artiste, un album, un concert, un ticket, etc. Et aussi ... ce qu'est une facture !
Ces vocabulaires et ontologies couvrent des entités au même titre que
Wikidata qui assigne pour chacune d'entre elles un identifiant unique
[1] .
Par exemple, vous trouverez une définition de ce qu'est une facture aux URLs
suivantes : Invoice pour schema.org (string(59) "RESULT IS CACHED ... RESULKT IS CACHED ... RESULT IS CACHED"
Un relevé des sommes dues pour des biens ou des services ; une facture
) et
Q190581 pour Wikidata (string(59) "RESULT IS CACHED ... RESULKT IS CACHED ... RESULT IS CACHED"
Document commercial délivré par un vendeur à un acheteur, relatif à une transaction de vente et indiquant les produits, les quantités et les prix convenus pour les produits ou les services que le vendeur a fournis à l'acheteur.
). Rien que
dans les définitions données par ces deux sources vous pourrez trouver un
ensemble de mots qui font sens – string(59) "RESULT IS CACHED ... RESULKT IS CACHED ... RESULT IS CACHED"
vente, transaction, produits, quantités, prix, &hellip ; – (et, parlant de
factures sur Internet, sur un site que vous construisez par exemple, vous
pouvez vous inspirer de tels mots pour améliorer votre ranking en matière de
moteurs de recherche, d'autant que schema.org est d'abord une
initiative de tels moteurs). Vous servir de toutes ces propriétés et entités,
du vocabulaire dégagé, des ontologies qui forment des catégories de sujets,
tout ceci vous permet aussi de donner à vos procédures OCR — Optical Character Recognition l'intelligence nécessaire pour comprendre
la nature d'un document, pour le classer automatiquement, pour le router au
sein de votre organisation.
En informatique, les ontologies sont notamment employées dans le Web sémantique et en Intelligence Artificielle pour saisir, comprendre un domaine particulier. Chaque domaine est décrit en se référant aux types d'objets qui le composent (les classes) et à leurs propriétés (ou attributs). Lesdits objets entretiennent des liens entre eux (des relations) et répondent à des événements qui induisent des changements dans leurs propriétés ou dans leur relation les uns aux autres. Elles sont essentielles à qui souhaite entamer une Transformation Digitale sérieuse.
Les ontologies sont un endroit où convergent de multiples techniques comme par exemple le OWL — Web Ontology Language , un langage de représentation des connaissances fonctionnant sur la base de RDF — Resource Definition Framework, un modèle de graphe destiné à décrire les ressources Web et permettre ainsi leur traitement automatique. C'est un champ large du domaine informatique, totalement essentiel dans la compréhension des langages naturels.
Web sémantique
Je ferai un passage très bref par Web sémantique car ce ne constitue pas le cœur de mon thème. Néanmoins, ce sujet n'est pas mineur car un site web bien construit, qui fasse du sens pour humains et robots, est une garantie d'exposition universelle.
En plus de servir de répertoire d'entités parfaitement décrites au niveau de leurs propriétés et de leur héritage (au sens de la programmation orientée-objets), schema.org fournit nombre d'exemples qui permettent de mieux qualifier ce qui se cache aux tréfonds d'un code HTML.
Voyez par exemple comment présenter une facture en HTML avec référence au vocabulaire de schema.org (et donc … compréhension partagée des informations qui sont renseignées) :
<div itemscope itemtype="http://schema.org/Invoice">
<h1 itemprop="description">New furnace and installation</h1>
<div itemprop="broker" itemscope itemtype="http://schema.org/LocalBusiness">
<b itemprop="name">ACME Home Heating</b>
</div>
<div itemprop="customer" itemscope itemtype="http://schema.org/Person">
<b itemprop="name">Jane Doe</b>
</div>
<time itemprop="paymentDueDate">2015-01-30</time>
<div itemprop="minimumPaymentDue" itemscope itemtype="http://schema.org/PriceSpecification">
<span itemprop="price">0.00</span>
<span itemprop="priceCurrency">USD</span>
</div>
<div itemprop="totalPaymentDue" itemscope itemtype="http://schema.org/PriceSpecification">
<span itemprop="price">0.00</span>
<span itemprop="priceCurrency">USD</span>
</div>
<link itemprop="paymentStatus" href="http://schema.org/PaymentComplete" />
<div itemprop="referencesOrder" itemscope itemtype="http://schema.org/Order">
<span itemprop="description">furnace</span>
<time itemprop="orderDate">2014-12-01</time>
<span itemprop="orderNumber">123ABC</span>
<div itemprop="orderedItem" itemscope itemtype="http://schema.org/Product">
<span itemprop="name">ACME Furnace 3000</span>
<meta itemprop="productID" content="ABC123" />
</div>
</div>
<div itemprop="referencesOrder" itemscope itemtype="http://schema.org/Order">
<span itemprop="description">furnace installation</span>
<time itemprop="orderDate">2014-12-02</time>
<div itemprop="orderedItem" itemscope itemtype="http://schema.org/Service">
<span itemprop="description">furnace installation</span>
</div>
</div>
</div>
Cette information est complètement désambigüisée. Un robot informatique fait la différence entre chaque zone. Par exemple, toutes les zones de date sont parfaitement établies : on sait ce qui est la date du paiement, ce qu'est la date de la commande, …
Je vous laisse visiter Product qui fournit nombre d'exemples d'expressions sémantiques : Microdata, RDFa, JSON-LD. Reprenant cette façon de présenter votre catalogue de produits, vous vous assurez une information pertinente reprise dans les moteurs de recherche. Ce n'est pas rien !
Je ne résiste pas à la tentation de vous donner encore un dernier exemple : un événement, encore extrait de schema.org : Event … et quelle est l'entreprise/organisation d'une certaine taille qui n'organise pas d'événement ? Sachez présenter l'information de manière structurée pour la voir correctement répertoriée dans les moteurs de recherche et les réseaux sociaux !
<div itemscope itemtype="http://schema.org/TouristAttraction">
<h1><span itemprop="name">Musée Marmottan Monet</span></h1>
<div>
<span itemprop="description">It's a museum of Impressionism and french ninenteeth art.</span>
</div>
<div itemprop="event" itemscope itemtype="http://schema.org/Event">It is hosting the
<span itemprop="about">Hodler</span>'s
<span itemprop="about">Monet</span>'s
<span itemprop="about">Munch</span>'s exibit:
<span itemprop="name">"Peindre l'impossible"</span>.
<meta itemprop="startDate" content="2016-09-15" />Start date: September 15 2016
<meta itemprop="endDate" content="2017-01-22" />End date: Genuary 22 2017
</div>
</div>
Vous aurez compris tout l'intérêt, j'imagine, de l'utilisation des entités définies dans schema.org
Et les autres…
Freebase
D'autres initiatives que schema.org existent qui d'ailleurs modélisent le
monde avec un spectre plus large encore. Freebase par exemple
qui couvre pratiquement 39 millions de sujets (topics) comme des personnes
(Bob Dylan par exemple — /m/01vrncs), des lieux
(Bruxelles par exemple — /m/0177z) et des choses (un
camion par exemple — /m/07r04).
Geni
Allons plus avant avec Bob Dylan si vous le voulez bien. Pour ce chanteur
porte-paroles de sa génération vous pouvez vous adresser au répertoire
geni.com : car Bob
Dylan y est effectivement connu sous l'ID 6000000017944190389.
Un autre répertoire ouvert dont il est possible d'extraire de l'information.
Le cas de Bob Dylan est parfaitement exemplaire de ce que j'essaie de vous exposer et illustre bien mon propos général qui est d'indiquer à quel point les informaticiens peuvent tirer profit de ces ontologies, vocabulaires et autres répertoires généraux qui modélisent le monde.
Sur la radio web, TRQL Radio, j'ai programmé un système
d'annonces/désannonces automatiques. Cela signifie qu'un programme parcourt la
playlist du jour (elle-même constituée entièrement automatiquement), examine les
morceaux et "annonce" le morceau suivant ou "désannonce" un ou plusieurs
morceaux précédent(s). Imaginons que l'un de ces morceaux soit de … Bob Dylan. Le
programme peut alors chercher s'il y a quelque chose à dire sur le chanteur
américain. Le programme a le choix entre plusieurs sources d'informations.
Posons qu'il choisit l'identifiant Freebase, il aboutit dès
lors sur la page Freebase qui dit … Bob Dylan is an American singer-songwriter, artist, and writer. He has been influential in popular music and culture for more than five decades. […]
.
Le programme passe cette information à un moteur TTS — Text-To-Speech (Amazon Polly, par exemple) et vous obtenez une annonce (ou
désannonce) intelligente et AUTOMATIQUE à diffuser à l'antenne (Polly vous rend
un .mp3 qui n'est finalement en rien différent d'un morceau de musique
traditionnel : il vous est donc possible d'insérer l'annonce/désannonce dans la
playlist comme s'il s'agissait d'une chanson). Parfait exemple d'automatisation et
je simplifie même la donne car, au passage, on aurait très bien pu passer le
texte de Freebase à un moteur automatique de traduction; voici ce que cela
donnerait : string(59) "RESULT IS CACHED ... RESULKT IS CACHED ... RESULT IS CACHED"
Bob Dylan est un auteur-compositeur-interprète américain,
artiste et écrivain américain. Il a influencé la musique populaire et la culture
et la culture populaires depuis plus de cinq décennies. [...]
.
Wikidata. Ah, Wikidata !
Je ne quitte pas les autres initiatives similaires à schema.org pour maintenant me concentrer quelque peu sur Wikidata.
Wikidata est une base de données libre, collaborative, multilingue. Cette base de données contient des données structurées qui servent à alimenter Wikipédia, et toute une série d'autres projets dans le mouvement Wikimedia.
Les données de Wikidata sont publiées sous licence Creative Commons Transfert dans le Domaine Public (CC0 1.0) ce qui signifie que vous pouvez copier, modifier, partager et améliorer les données, même pour une utilisation commerciale, sans avoir à demander la permission.
J'ai publié un service générique qui interroge cet immense répertoire
d'entités. Bob Dylan y figure sous l'ID Q392. Voici son
URL : https://wikidata.org/wiki/Q392. Vous y apprenez
ceci : American recording artist, singer-songwriter, musician, author, artist
and and Nobel Laureate in 2016
. Vous avez là , malgré la petite faute du double
« and » [2] , une variation possible
d'annonces/désannonces automatiques.
Prenez la peine de consulter la quantité incroyable d'informations que vous
pouvez glaner sur Bob Dylan (ou tout autre sujet). Vous y verrez notamment
tous les noms d'emprunt de l'artiste, vous y verrez dans quels autres
répertoires il apparaît, vous y verrez que l'entité Bob Dylan,
connue donc sous la référence Q392, est une occurrence de l'entité
Être humain (propriété P31 veut dire instance of, ce que vous pouvez vérifier avec https://www.wikidata.org/w/api.php?action=wbgetentities&ids=P31&format=xml),
connue elle sous l'ID Q5 (https://www.wikidata.org/w/api.php?action=wbgetentities&ids=Q5&format=xml) qui
elle fait partie de l'entité Humanité (
À côté des répertoires que je viens de mentionner, il existe nombre de répertoires publics https://kbopub.economie.fgov.be/kbo-open-data/, https://www.data.gouv.fr/fr/, … Prenez la peine de regarder ce que vous pouvez en tirer. Voyez en quoi ces répertoires permettent dématérialisation, digitalisation, et … automatisation.
Travail de fourmi et … d'étude
En revanche, c'est un véritable travail de fourmi que de fouiller dans ces répertoires gigantesques, de les comprendre, de saisir les dépendances qui y sont introduites, de décortiquer le sens de chaque ID, etc. Une véritable étude, très profitable néanmoins. Pour ce qui est de Wikidata, la page suivante peut vous aider à vous y retrouver : https://hay.toolforge.org/propbrowse/
. Il n'est pas rare que les programmes doivent faire de multiples allers-retours entre de nombreux end-points pour constituer une vue qui fasse sens. Comme ces opérations sont chronophages il vient immédiatement à l'esprit de pouvoir « cacher » l'information obtenue et constituer des champs sémantiques tout-faits, directement prêts à l'emploi. C'est ce qui est fait sur TRQL Radio lorsqu'on rassemble nos connaissances en matière d'artistes. Nous avons une « base de données » d'environ 225000 artistes que nous souhaitons faire grimper à 400000 d'ici la fin de l'année 2020. Ces connaissances ont été extraites de multiples répertoires, ingérées , classées, structurées, comparées, annotées, appréciées, — pour former notre propre corpus, un corpus qui est revu régulièrement (la connaissance évolue constamment), un aspect importantissime que je ne souhaite pas débattre ici sous peine d'être par trop technique et lassant. Qu'il me suffise de dire que la connaissance accumulée dans un champ ontologique donné est comme la science : on sait ce qu'on sait jusqu'au moment où on sait qu'on s'est trompé. Cela implique donc une révision constante des connaissances engrangées.Concrètement…
Imaginons que TRQL Radio recherche les dates de naissance et de décès de
Jim Croce. Une recherche sur Wikidata nous apprend
que l'ID de Jim Croce (écrit Jim_Croce dans la
recherche) est Q464277. On se rend donc (par programmation) sur
la page qui décrit l'entité Jim Croce et on y cherche les propriétés
P19 (place of birth),
P3150 (birthday),
P569 (date of birth),
P1477 (birth name),
P570 (date of death),
P1196 (manner of death),
P20 (place of death),
P119 (place of burial), et
P509 (cause of death). Pour TRQL Radio ces
informations forment le squelette de ce que notre moteur de connaissances
enregistre. Je vais me concentrer sur les dates de naissance et de décès
pour la facilité de la démonstration, soient les propriétés P569
et P570 :
<property id="P569">
<datavalue type="time">
<value time="+1943-01-10T00:00:00Z" timezone="0" … />
</datavalue>
</property>
<property id="P570">
<datavalue type="time">
<value time="+1973-09-20T00:00:00Z" timezone="0" … />
</datavalue>
</property>
De manière assez similaire il est totalement possible de savoir quand un
groupe s'est formé. Prenez l'exemple des Doobie
Brothers : c'est l'entité Q506670 de Wikidata. Leur
date de formation est donnée par la propriété P571
(inception) et vous obtenez le XML suivant pour cette
propriété :
<property id="P571">
[…]
<datavalue type="time">
<value time="+1970-01-01T00:00:00Z" … >
</datavalue>
</property>
Les Doobies se sont donc formés en 1970. Vous êtes alors capable de créer
une annonce intelligente comme «% artist.name%, formed in
%artist.inception%, on %radio%! Only music; no blahblah! ».
Cette phrase-type, dont il s'agira de substituer les parties variables, peut
connaître de multiples alternances. Ceci s'inscrit dans la Transformation
Digitale de TRQL Radio, ce qui introduit le débat qui suit …
Pour quoi faire ?
Vous pouvez vous demander avec raison en quoi ce genre de forage dans les arcanes de schema.org, Wikidata, et autres répertoires, est susceptible de donner une sorte d'avantage compétitif à l'orgabnisation qui la pratique. Vous êtes en droit de vous poser la question du « Pourquoi ? ».
Dans le cas de TRQL Radio — un exemple parmi d'autres — ,
l'avantage compétitif réside dans la capacité à détecter et utiliser ce ces
informations sans devoir y consacrer le moindre temps humain (ce sont des
programmes qui sont continuellement en recherche de l'information). C'est un
gain de temps considérable.
Le recours à des répertoires externes accessibles librement permet d'envisager de nombreuses automatisations. En environnement bancaire, le recours à différents répertoires a permis d'automatiser l'approbation de demandes de crédit (par exemple en consultant le fichier central des avis de saisie, de délégation, de cession et de règlement collectif de dettes). Pour TRQL Radio, le recours aux répertoires déjà mentionnés a permis de créer des annonces/désannonces intelligentes (voir plus haut), voir même créer des hommages automatiques (tributes). Michael Jackson est né le 29 août 1958 et est décédé le 25 juin 2009. Ces infos sont faciles à obtenir depuis le répertoire d'entités de Wikidata; on peut donc créer des hommages automatiques (une petite série de titres) en mémoire du roi de la pop lorsqu'on est en présence d'une de ces dates : la création des playlists est automatisée ! Voici d'ailleurs de quoi obtenir 1h d'hommage à Michael Jackson sur TRQL Radio. Voyons de quoi il s'agit d'un point de vue compétitif:
- Détection des dates automatiques : un programme cherche les dates de naissance et de décès d'artistes pour un jour donné. Automatique : 44 sec; Manuel : 60 min.
- Chaque artiste renseigné fait l'objet d'une vérification : artiste connu ou non. Automatique : 0 sec (est fait avec l'étape 1); Manuel : 15 min.
- Si artiste connu, vérification du nombre de titres disponibles (en a-t-on au moins 3 ?). Automatique : 4 sec; Manuel : 2 min.
- Si nombre de titres disponibles supérieur ou égal à 3, création d'un hommage. Automatique : 2 sec; Manuel : 15 min.
- Insertion de l'hommage dans la playlist du jour. Automatique : 0.02 sec; Manuel : 15 min.
Au total, ce travail représente 50,02 sec en mode automatique; il représente 107 min en mode manuel, soit 6420 sec, soit un facteur 128 !
Chacun doit examiner avec ouverture d'esprit ce que ces répertoires
peuvent apporter à son propre cœur d'affaires. Comme le disait dernièrement
très justement un ami, il vaut mieux aimer ses problèmes que ses
solutions
. En tout demeure la question du « Why ? » et ce n'est
certainement pas Simon Sinek qui me contredira. Poser cette question et y
répondre vous appartiennent !
Vos premiers pas avec schema.org
Pour vous aider à faire vos premiers pas avec schema.org, je vous livre ici 2 fichiers XML qui listent les classes couvertes et leurs propriétés. Personnellement, je me suis servi de ces 2 fichiers pour générer AUTOMATIQUEMENT plus de 900 classes PHP qui font ainsi partie de mon arsenal de développement.
Par ailleurs, vous trouverez aussi un fichier XML qui liste les propriétés de Wikidata, ce qui s'avère utile pour interroger ce répertoire (savoir que date de naissance c'est la propriété P569, que la date de décès c'est P570, etc.) : 7864 propriétés disponibles.
Les services utilisables immédiatement (en droite ligne de TRQL Radio)
Pour contribuer à votre effort d'utilisation de ces répertoires ouverts et publics, je vous livre 3 services d'accès à Wikipedia/Wikidata : de quoi chercher ce que Wikipedia détient sur un terme (ou ensemble de termes), chercher les entités correspondant à un terme ou des termes (Elvis Presley, par exemple), et de quoi obtenir le détail d'une entité/propriété.
wikipedia-search (alias Wikipedia)
Ce service permet de connaître tout ce que Wikipedia connaît sur un terme (ou ensemble de termes) – les termes doivent être mentionnés en anglais :
- Infos concernant « Fleetwood Mac »
- Aucun résultat attendu car le query est basé sur autre chose que des termes anglais
- Même query mais en anglais, cette fois-ci avec nombre de résultats.
- Que sait Wikipedia de schema.org ? On voit par
exemple que schema.org a un Wikidata ID :
Q3475322(utile pour d'autres types de consultations)
wikidata-search
Ce service retourne les entités qui matchent le(s) terme(s) de la recherche. Ne pas confondre avec wikipedia-search. Seul l'anglais est supporté par le service.
- Toutes les entités qui matchent Vitrival.
- Toutes les entités matchant Bob Dylan.
- Toutes les entités matchant Invoice.
- Toutes les entités matchant BNP Paribas.
wikidata-entity
Ce service permet de connaître la définition d'une entité ou d'une propriété :
- Bob Dylan est connu sous l'ID Q392 dans Wikidata. Voilà de quoi extraire tout ce que Wikipedia sait de Bob Dylan.
- La propriété qui permet de savoir quel est l'ID Facebook d'une entité. Grâce à cela, on sait à quoi correspondent les propriétés qu'on cherche. Ici, on cherche la définition de la propriété P2013.
- La description de la propriété P569 … la date de naissance en fait, une propriété qui ne sera présente qu'au sein d'entités où une date de naissance a du sens.
- L'entité qui décrit Vitrival, là où l'auteur de ce site habite.
Notes de bas de page
[1] … Ces identifiants sont largement utilisés par les analyseurs de langage naturel pour se forger une représentation concrète des concepts qui parsèment les textes qui leur sont soumis
[2] … Je n'ai pas voulu corriger cette faute volontairement. Il se pourrait aussi, au moment où vous suivez le lien, que Wikidata aie remanié le texte


